List of Open Source and Free Data Mining Platforms
Here is a list Open Source and Free Data Mining Platforms
(Taken from http://butleranalytics.com/ )
Free data mining software ranges from complete model development environments such as Knime and Orange, to a variety of libraries written in Java, C++ and most often in Python. The list below provides summaries of the most popular alternatives.
Apache Mahout supports mainly three use cases: Recommendation mining takes users' behavior and from that tries to find items users might like. Clustering takes e.g. text documents and groups them into groups of topically related documents. Classification learns from exisiting categorized documents what documents of a specific category look like and is able to assign unlabelled documents to the (hopefully) correct category.
Data.Mining.Fox (DMF) from easydatamining is a free data mining tool that hides much of the background complexity. The interface takes users through several well defined steps from data import through to predictions based on new data.
The Databionic ESOM Tools is a suite of programs to perform data mining tasks like clustering, visualization, and classification with Emergent Self-Organizing Maps (ESOM).
The gnome-datamine-tools is a growing collection of tools packaged to provide a freely available single collection of data mining tools.
Jubatus is the first open source platform for online distributed machine learning on the data streams of Big Data. Jubatus uses a loose model sharing architecture for efficient training and sharing of machine learning models, by defining three fundamental operations; Update, Mix, and Analyze, in a similar way with the Map and Reduce operations in Hadoop.
KEEL is an open source (GPLv3) Java software tool to assess evolutionary algorithms for Data Mining problems including regression, classification, clustering, pattern mining and so on. It contains a big collection of classical knowledge extraction algorithms, preprocessing techniques (training set selection, feature selection, discretization, imputation methods for missing values, etc.), Computational Intelligence based learning algorithms, including evolutionary rule learning algorithms based on different approaches (Pittsburgh, Michigan and IRL, ...), and hybrid models such as genetic fuzzy systems, evolutionary neural networks, etc.
Knime is a widely used open source data mining, visualization and reporting graphical workbench used by over 3000 organisations. Knime desktop is the entry open source version of Knime (other paid for versions are for organisations that need support and additional features). It is based on the well regarded and widely used Eclipse IDE platform, making it as much a development platform (for bespoke extensions) as a data mining platform.
MALLET is a Java-based package for statistical natural language processing, document classification, clustering, topic modeling, information extraction, and other machine learning applications to text.
ML-Flex uses machine-learning algorithms to derive models from independent variables, with the purpose of predicting the values of a dependent (class) variable.
Mlpy is a Python module for Machine Learning built on top of NumPy/SciPy and the GNU Scientific Libraries. mlpy provides a wide range of state-of-the-art machine learning methods
for supervised and unsupervisedproblems and it is aimed at finding a reasonable compromise among modularity, maintainability, reproducibility, usability and efficiency.
Modular toolkit for Data Processing (MDP) is a library of widely used data processing algorithms that can be combined according to a pipeline analogy to build more complex data processing software. Implemented algorithms include Principal Component Analysis (PCA), Independent Component Analysis (ICA), Slow Feature Analysis (SFA), and many more
Orange is a very capable open source visualization and analysis tool with an easy to use interface. Most analysis can be achieved through its visual programming interface (drag and drop of widgets) and most visual tools are supported including scatterplots, bar charts, trees, dendograms and heatmaps. A large number (over 100) of widgets are supported.
R is a programming language, but there are literally thousands of libraries that can be incorporated into the R environment making it a powerful data mining environment. In reality R is probably the most flexible and powerful data mining environment available, but it does require high levels of skill.
Rattle (the R Analytical Tool To Learn Easily) presents statistical and visual summaries of data, transforms data into forms that can be readily modelled, builds both unsupervised and supervised models from the data, presents the performance of models graphically, and scores new datasets.
RapidMiner is perhaps the most widely used open source data mining platform (with over 3 million downloads). It incorporates analytical ETL (Extract, Transform and Load), data mining and predictive reporting. The free version is now throttled and is called the trial version.
python scikit learn provides many easy to use tools for data mining and analysis. It is built on python and specifically NumPy, SciPy and matplotlib.
Shogun machine learning toolbox's focus is on large scale kernel methods and especially on Support Vector Machines (SVM). It provides a generic SVM object interfacing to several different SVM implementations, among them the state of the art OCAS, Liblinear, LibSVM, SVMLight, SVMLin and GPDT. Each of the SVMs can be combined with a variety of kernels. The toolbox not only provides efficient implementations of the most common kernels, like the Linear, Polynomial, Gaussian and Sigmoid Kernel but also comes with a number of recent string kernels as e.g. the Locality Improved, Fischer, TOP, Spectrum, Weighted Degree Kernel (with shifts).
TANAGRA is a free DATA MINING software for academic and research purposes. It proposes several data mining methods from exploratory data analysis, statistical learning, machine learning and databases area.
Vowpal Wabbit is the essence of speed in machine learning, able to learn from tera feature datasets with ease. Via parallel learning, it can exceed the throughput of any single machine network interface when doing linear learning, a first amongst learning algorithms.
WEKA is set of data mining tools is incorporated into many other products (Knime and Rapid Miner for example), but it also a stand-alone platform for many data mining tasks including preprocessing, clustering, regression, classification and visualization. The support for data sources is extended through Java Database Connectivity, but the default format for data is the flat file.
Friday 10 April 2015
Wednesday 12 March 2014
Aadhar Count

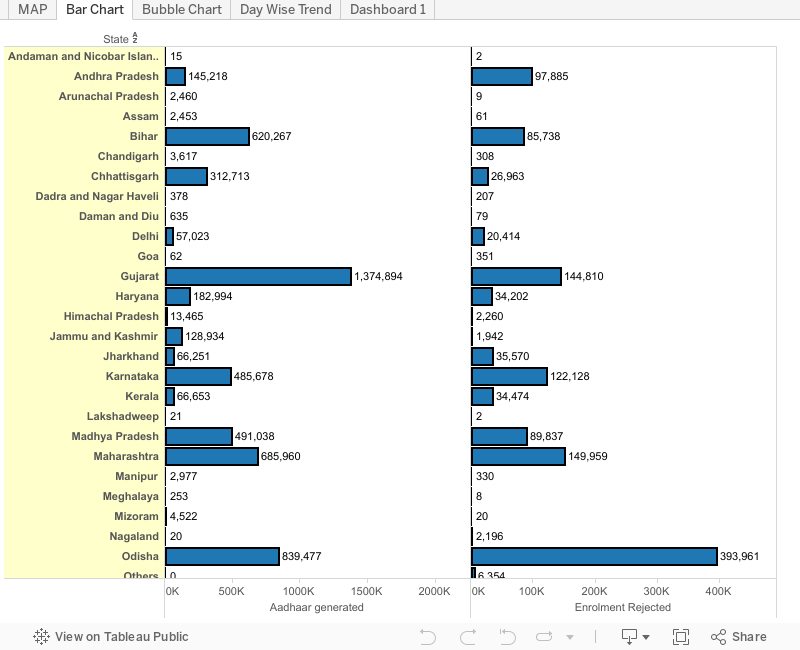
Friday 21 February 2014
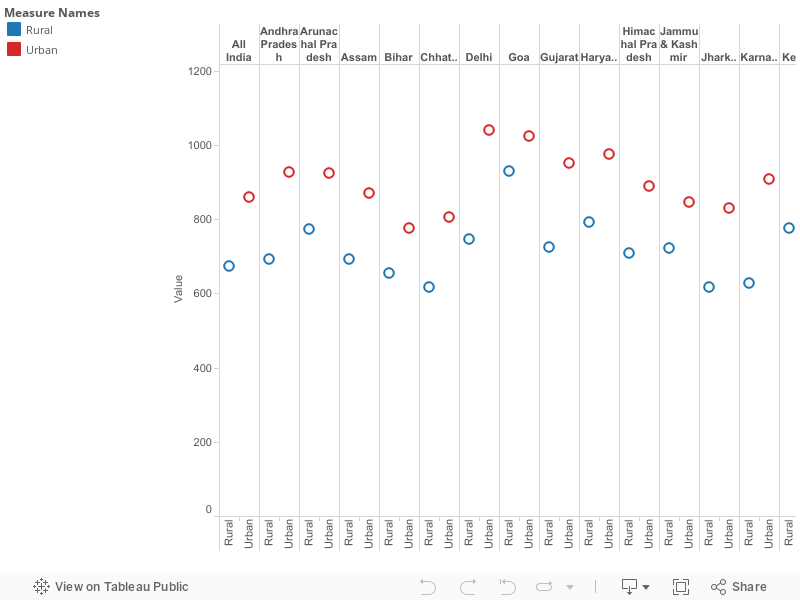
Sunday 9 February 2014
Monday 27 January 2014
Thursday 23 January 2014
<head>
<script type="text/javascript" src="https://www.google.com/jsapi"></script>
<script type="text/javascript">
google.load("visualization", '1', {packages:['corechart']});
google.setOnLoadCallback(drawChart01);
function drawChart01() {
var query = new google.visualization.Query(
'https://docs.google.com/spreadsheet/ccc?key=0Autj6tQDIzyCdFRXYjdZMm1BMWFCd0hoZ3R2NTh2RWc#gid=0=Demo1&range=B3:C15&headers=1');
query.setQuery('select B,C');
query.send(handleQueryResponse01);
}
function handleQueryResponse01(response) {
if (response.isError()) {
alert('Error in query: ' + response.getMessage() + ' ' + response.getDetailedMessage());
return;
}
var options = {
title: 'No of Beds Vs. Full Time Employees in Hospitals',
vAxis: {title: 'No of Beds', titleTextStyle: {color: 'red'}},
width: 600,
height : 800
};
var data = response.getDataTable();
var chart = new google.visualization.BarChart(document.getElementById('ChartSpan4'));
chart.draw(data, options );
}
</script>
<title>Sheet 2 Chart - Sheet, Range, Cols</title>
</head>
<body>
<span id='ChartSpan4'></span>
</body>
Wednesday 15 January 2014
Subscribe to:
Posts (Atom)